Talk to your database. In plain language.
Ask questions in natural language. Get instant data insights from MongoDB and MySQL. Without writing a single query.
Quick Start
Up and running in a coffee break
Connect your database, activate collections or tables, and start querying in natural language. Works with MongoDB and MySQL.
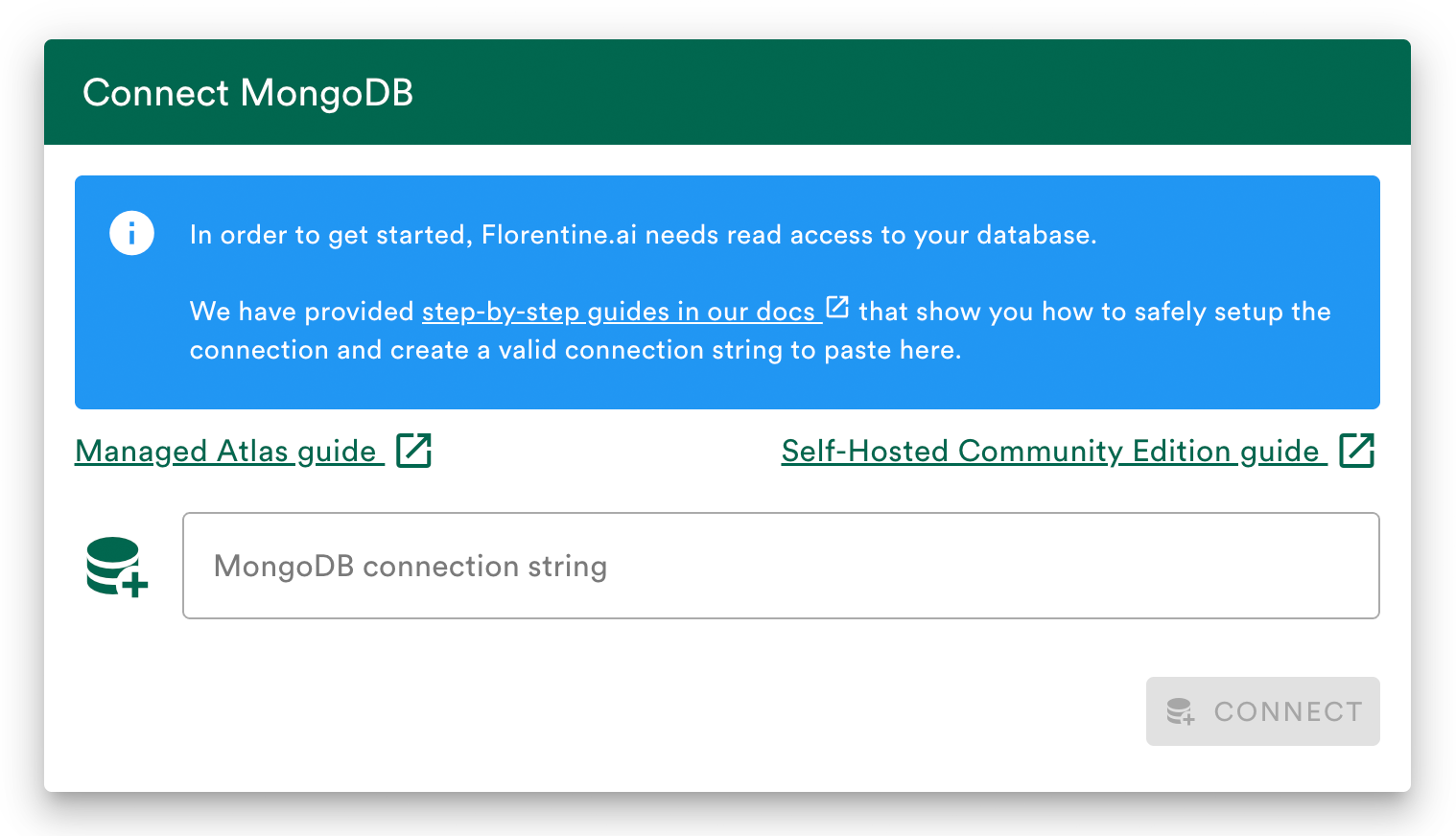
Connect your database
Add your MongoDB Atlas, MongoDB Community Edition or MySQL connection string.
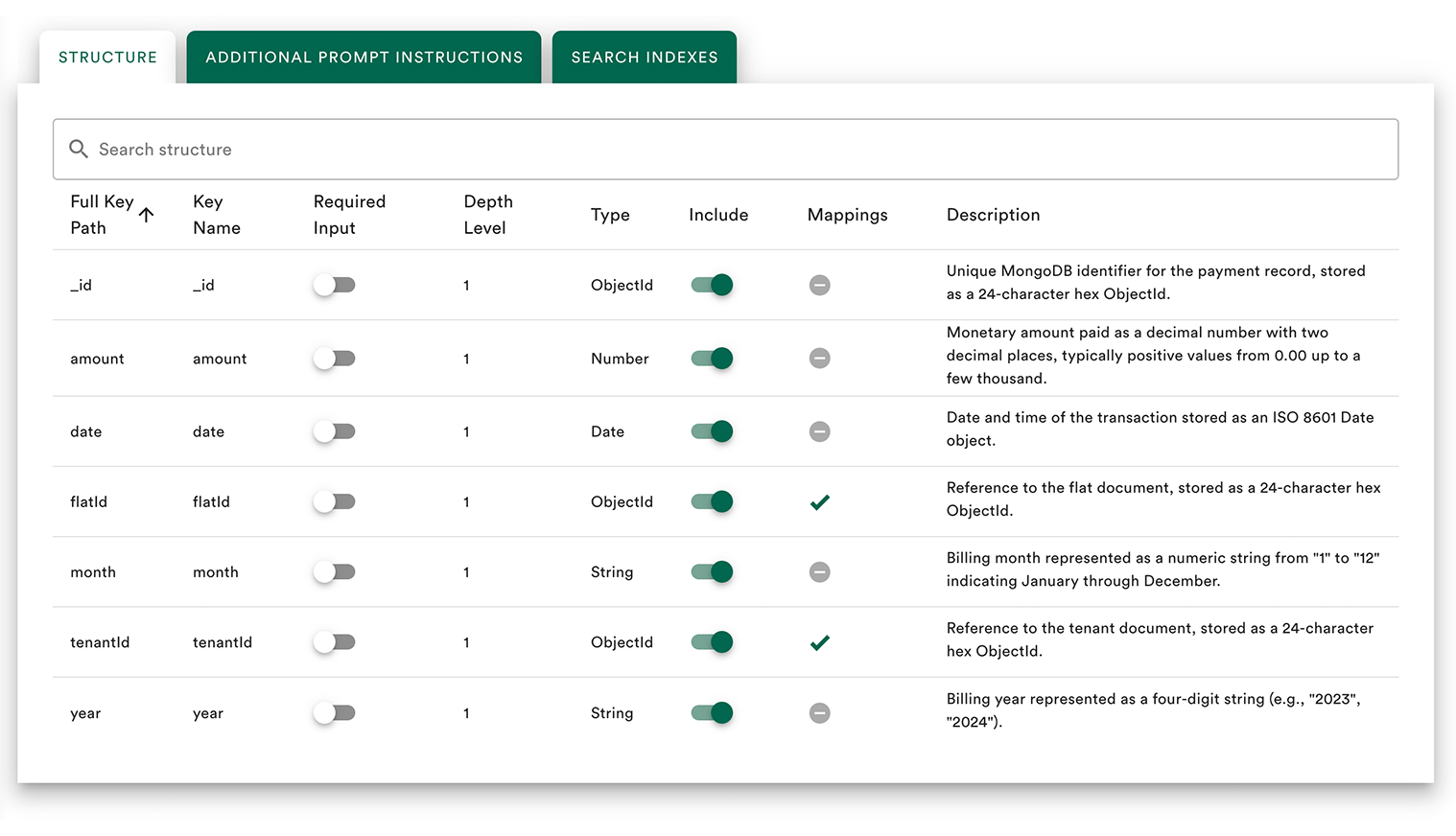
Activate collections or tables
Florentine automatically explores and analyzes your schema. Simply activate the collections or tables you want to query.
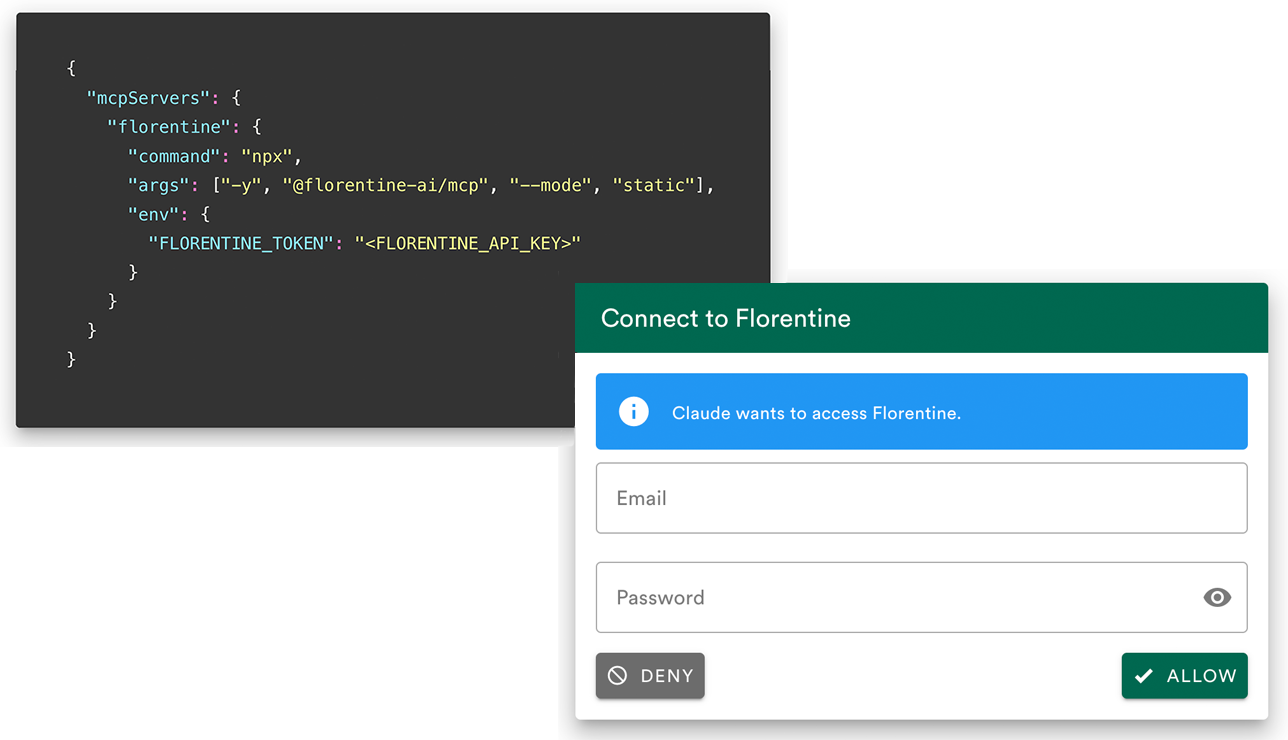
Integrate via MCP
Use the MCP Server to connect with AI agents like Claude, ChatGPT or custom made agents. Authenticate securely via OAuth2 or API key.
Supported Databases
One interface, multiple databases
Florentine understands the unique capabilities of each database and generates the right queries — aggregation pipelines for MongoDB, SQL for MySQL.
 Aggregation Pipelines
Aggregation PipelinesGenerates complex aggregation stages automatically
- Schema-aware Queries
Automatic schema exploration for accurate pipeline generation
- Vector Search / RAG
Semantic search with automated embedding creation and $vectorSearch support
- Secure data separation
Key/value based isolation on query level — enforced server-side, not by the LLM
- SQL Query Generation
Generates SQL queries optimized for data aggregation
- Schema Exploration
Analyzes tables, columns, and foreign key relationships automatically
- Secure data separation
Column value based isolation on query level — scopes data per tenant without LLM involvement
- Advanced JOIN Support
Automatically resolves relationships between tables with INNER, LEFT and RIGHT JOINs
Features & Concepts
Built for production use cases
Every feature is designed around real-world requirements: accuracy, privacy and seamless integration.
Response Control
Choose between raw query, query result, or natural language answer. Execute read-only queries automatically or review them first — you decide the level of control.
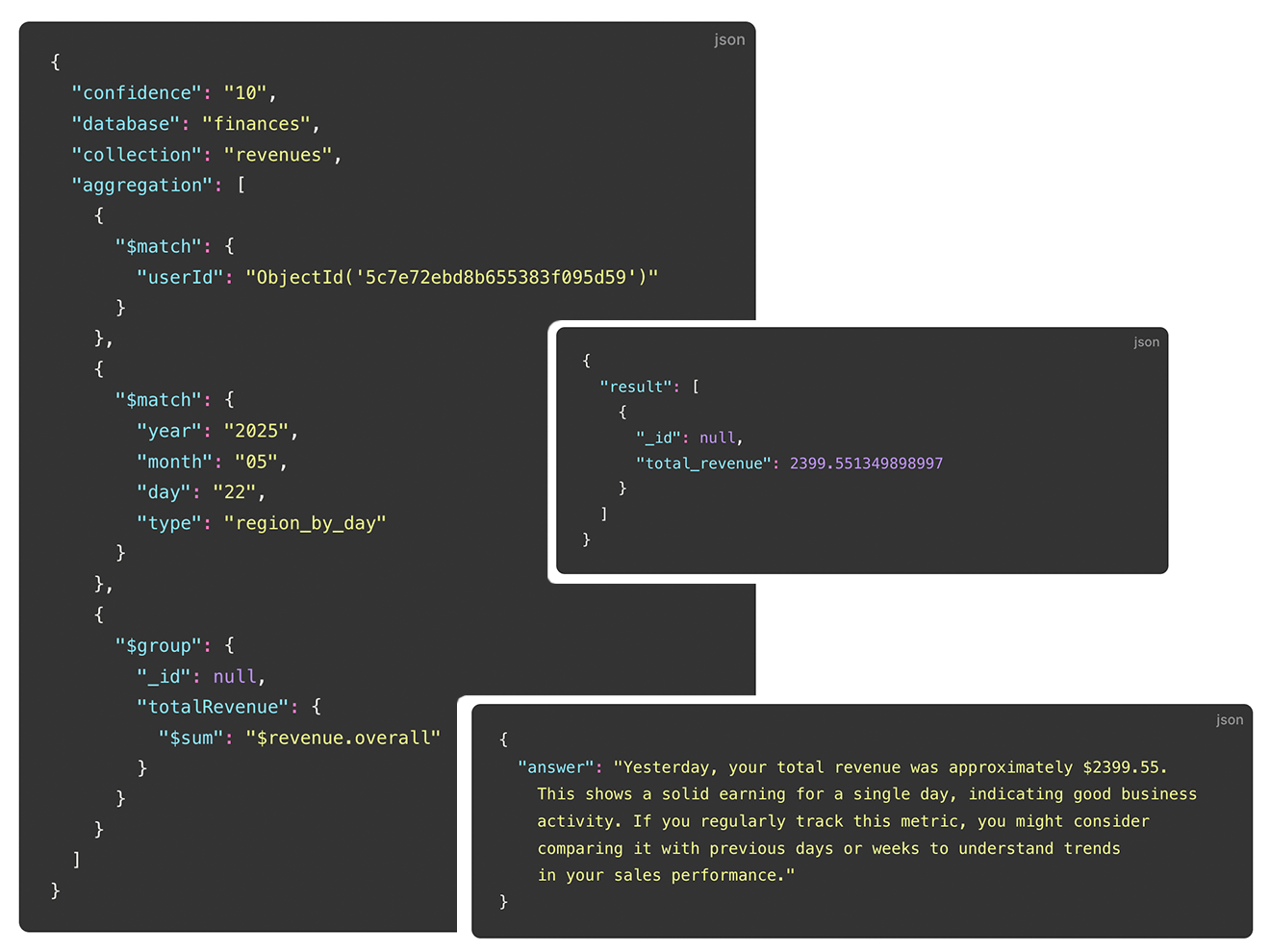
Schema Exploration
Florentine automatically explores and analyzes the schema of your collections and tables, enabling accurate, structure-aware query generation without sending your data to the LLM.
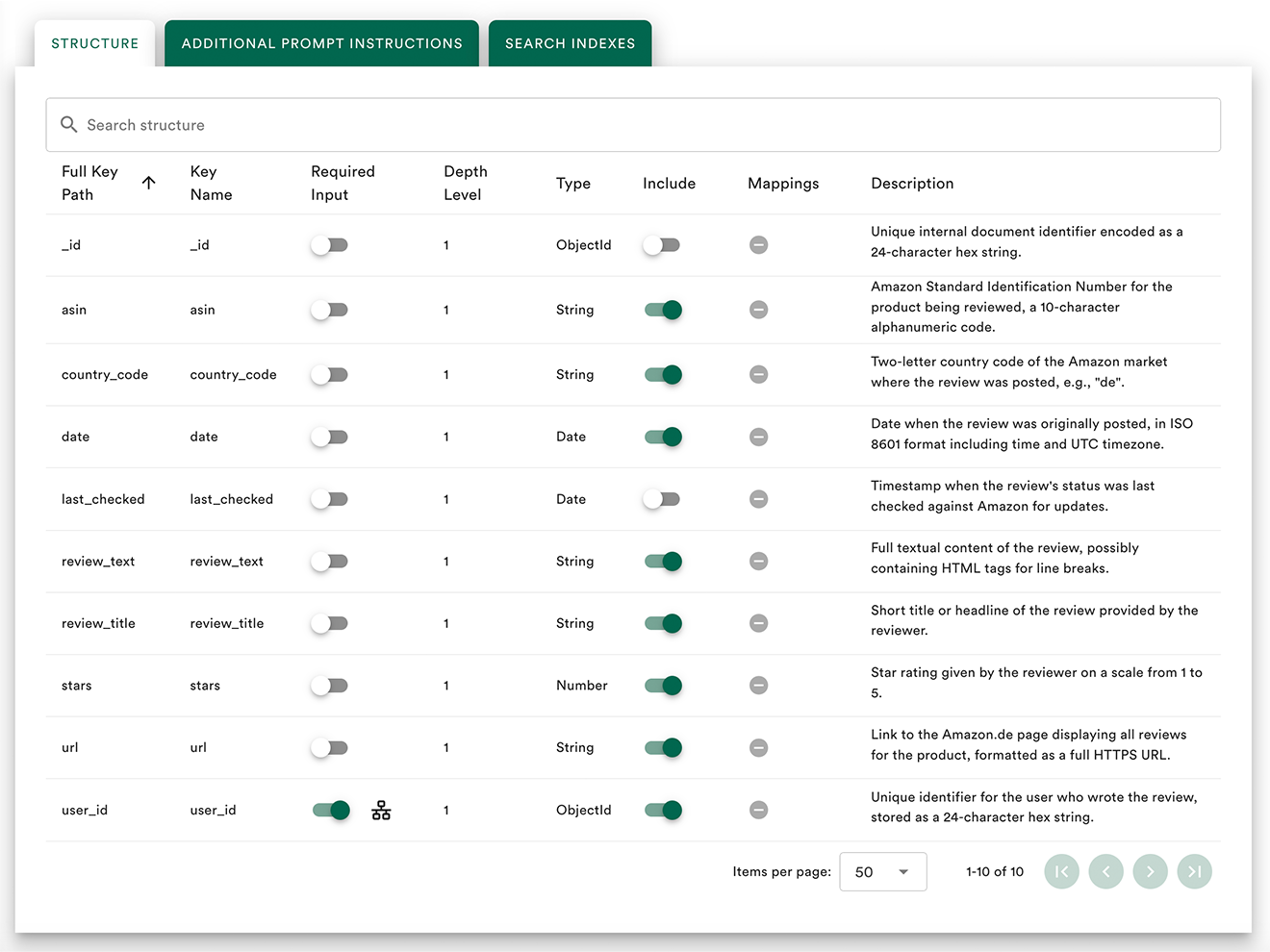
Secure Data Separation
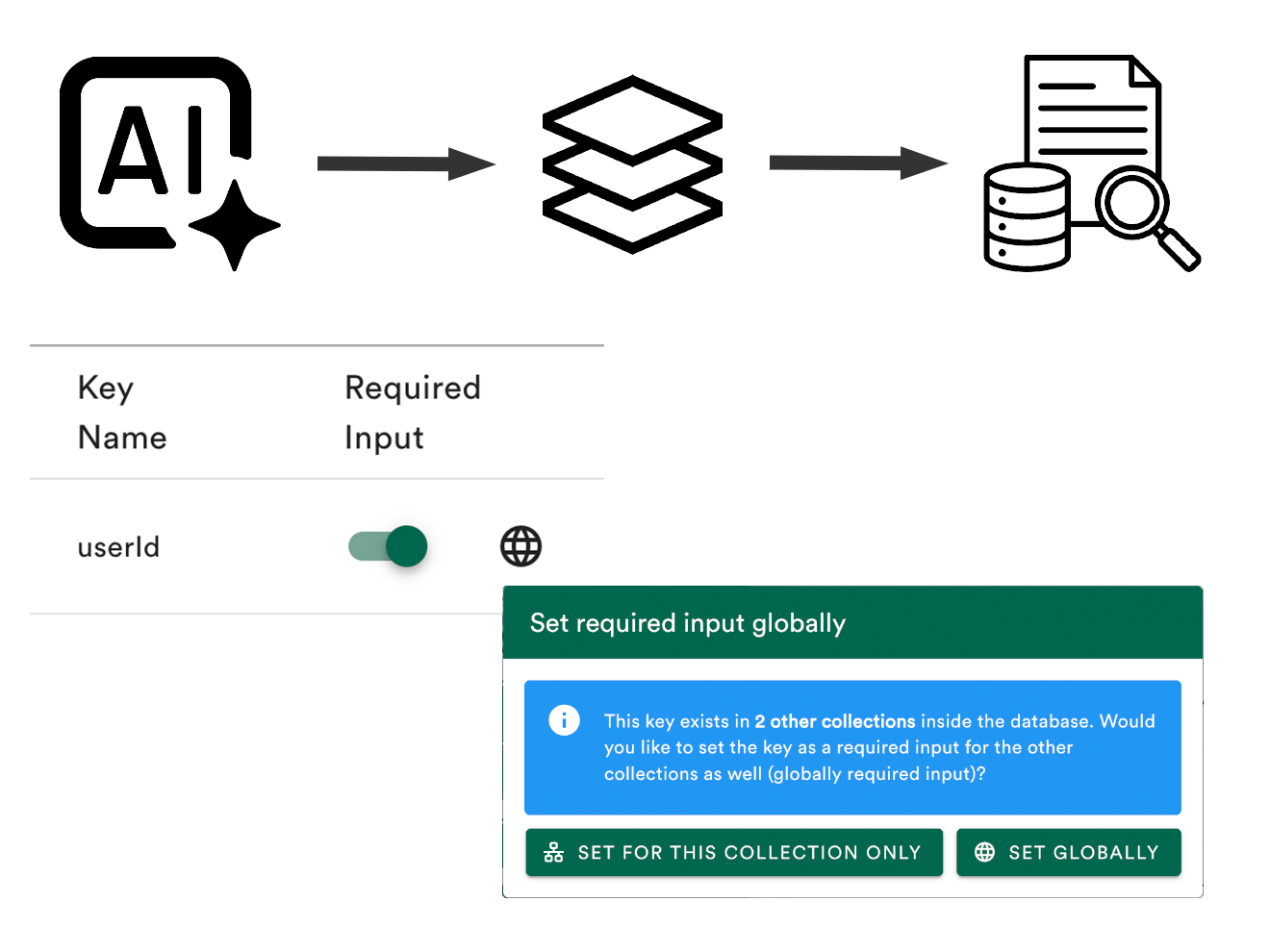
Key/value based isolation enforces mandatory filters in every query — no relying on LLM compliance. Perfect for multi-tenant SaaS applications.
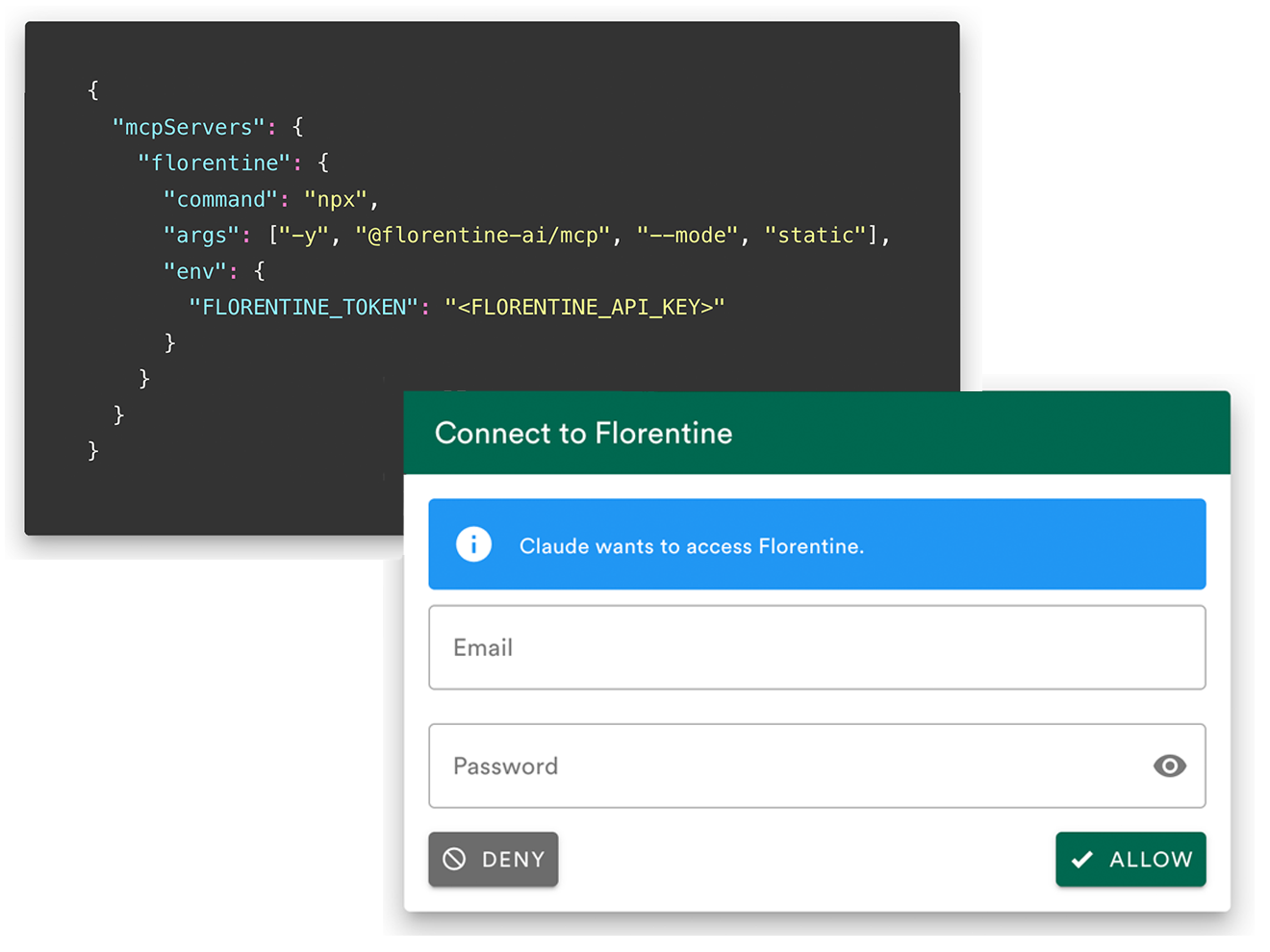
MCP Server & API
Integrate with Claude, Cursor, or any MCP-compatible agent via the MCP Server, or use the REST API to embed Florentine directly into your application.
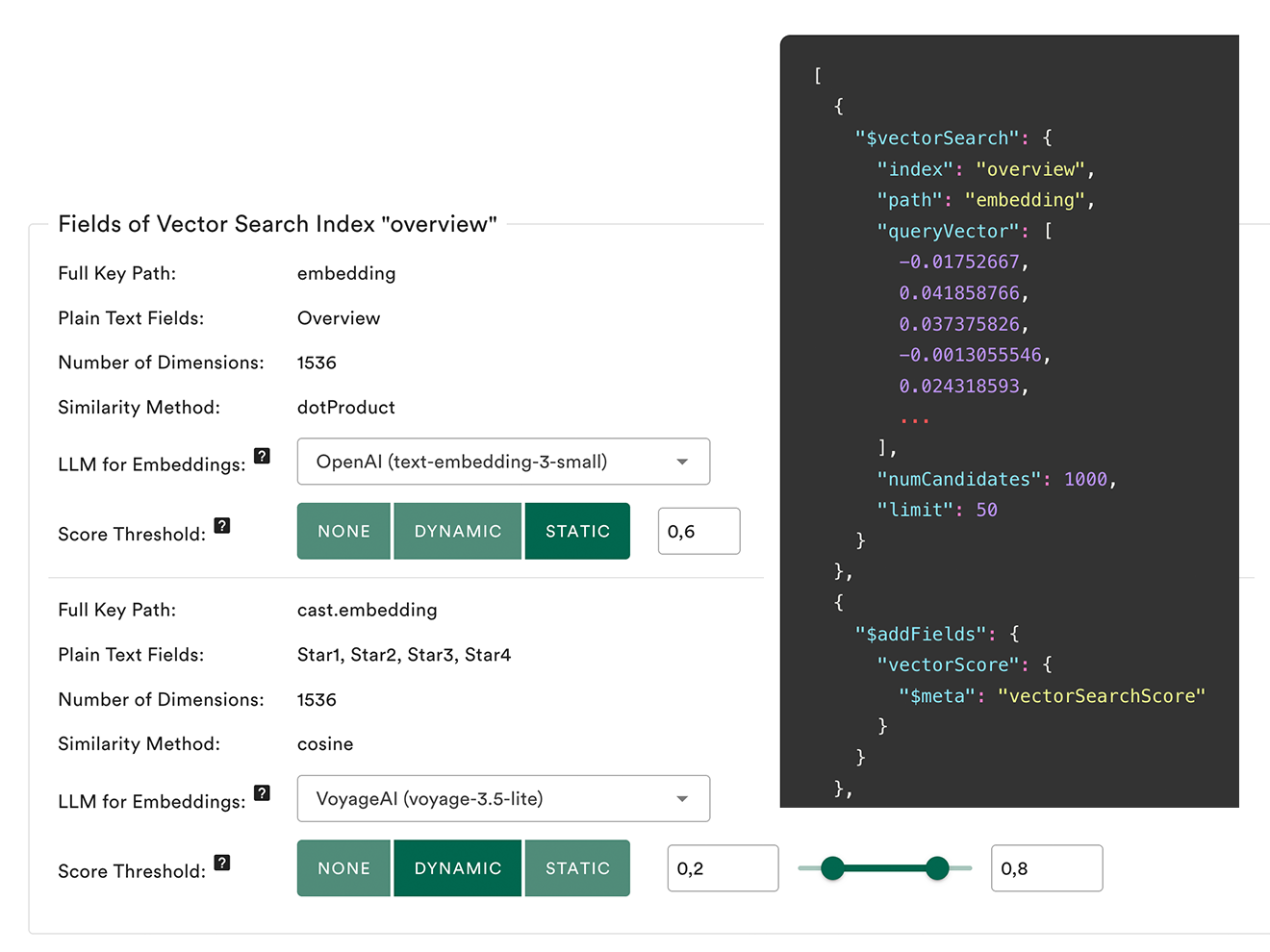
Vector Search & RAG
Supports semantic searches with automated embedding creation. Set custom score thresholds and use your own embeddings. (MongoDB only)
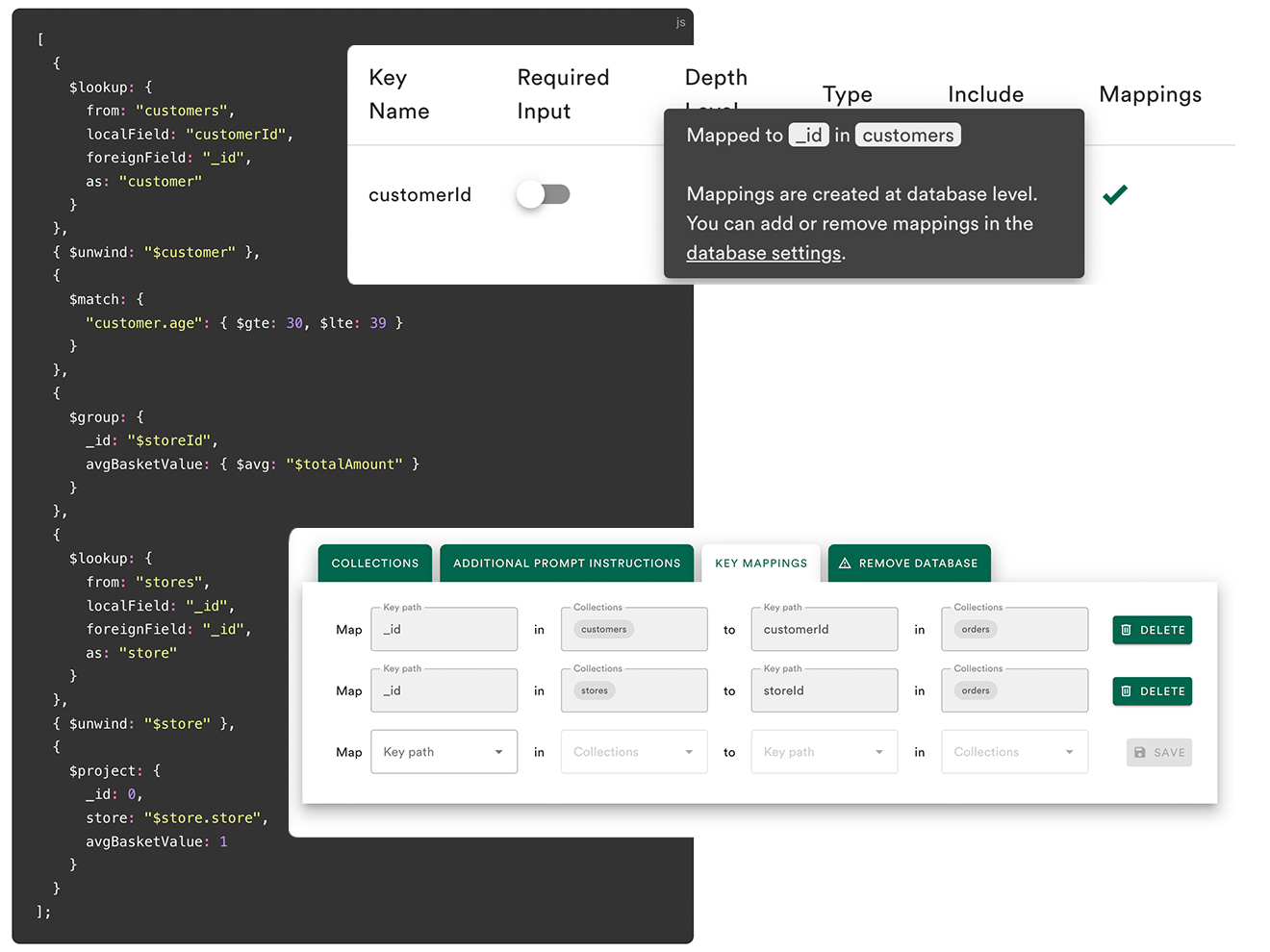
Advanced Lookup / JOIN Support
Automatically creates $lookup stages across MongoDB collections or JOINs across MySQL tables. Manual mapping assistance available for complex schemas.
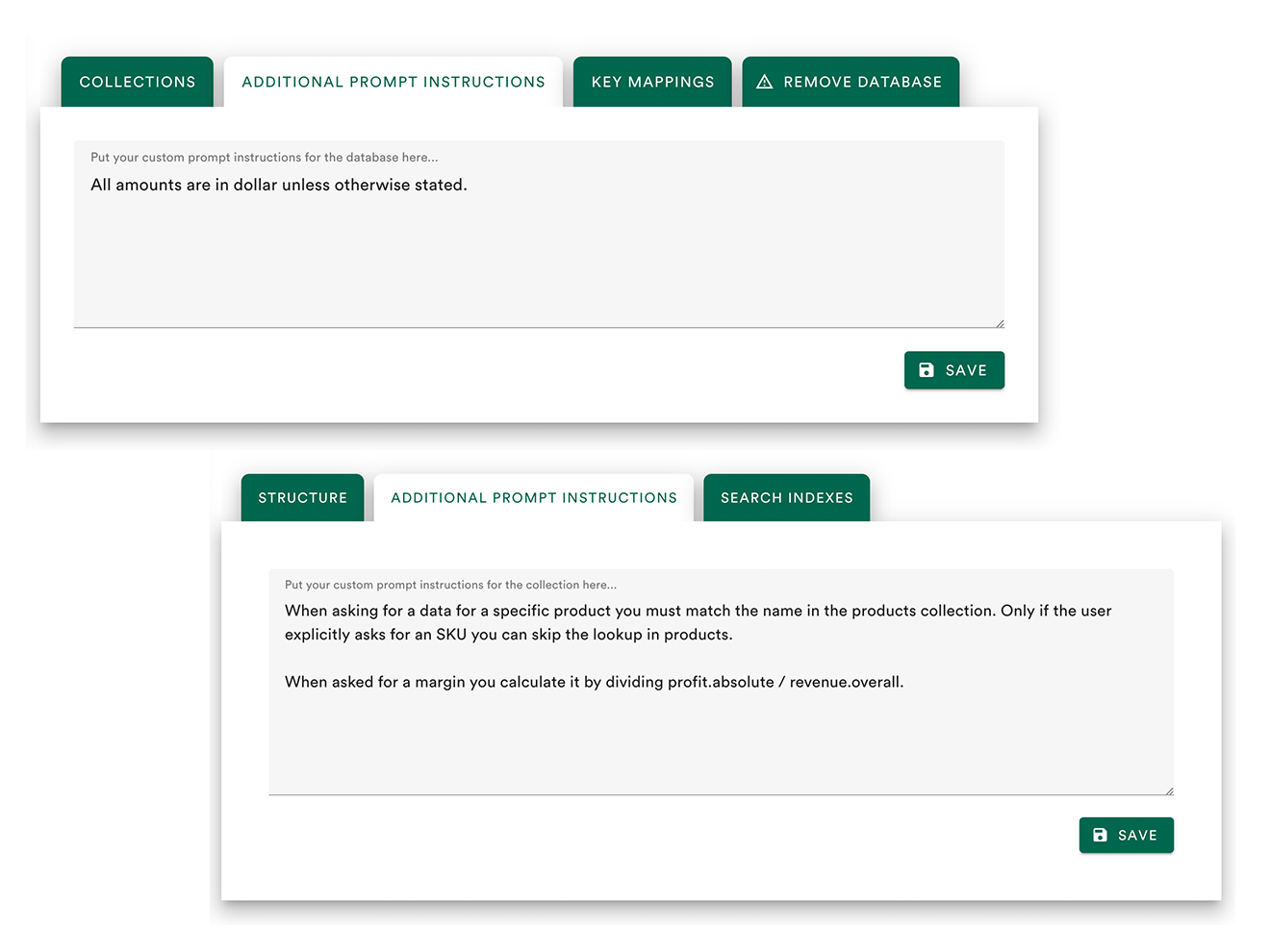
Custom Prompt Instructions
Control query behavior at the database or collection/table level with custom prompt instructions. Fine-tune exactly what the LLM should and should not do.
Use Cases
What teams use Florentine for
From customer support to data science — any team that needs to query a database benefits from Florentine's capabilities.
Customer Service
Let support teams query customer data in plain language — order history, account status, recent interactions — without any SQL or MongoDB knowledge required.
Analytics
Business analysts can explore data and build reports on the fly. Ask complex aggregation questions and get structured answers or natural language summaries.
Internal Search
Power internal knowledge bases and search tools. Find products, documents, and records through semantic search and natural language filters.
Recommendation Engines
Use Vector Search to find semantically similar items. Build recommendation engines that understand context — not just keywords — with automated embedding support.
Pricing
Simple, transparent pricing
All plans include MongoDB and MySQL support. Bring your own LLM API key — you control your AI costs.
Free
For individuals exploring their data. No credit card required.
- 1 database
- 5 active collections / tables
- 500 requests per month
- MongoDB & MySQL support
- MCP Server & API access
- Secure data separation
- Vector Search (MongoDB)
- $lookup / JOIN support
Pro
For teams that need more capacity and more active collections / tables.
- 1 database
- 25 active collections / tables
- 2,500 requests per month
- MongoDB & MySQL support
- MCP Server & API access
- Secure data separation
- Vector Search (MongoDB)
- $lookup / JOIN support
Enterprise
For organizations with multiple databases and high request volumes.
- 5 databases
- 50 active collections / tables
- 10,000 requests per month
- MongoDB & MySQL support
- MCP Server & API access
- Secure data separation
- Vector Search (MongoDB)
- $lookup / JOIN support
Need a more powerful plan or an on-premise solution? Just contact us.